數(shù)據(jù)來源的透明度 我的信息從何而來,又將去往何處?
在數(shù)字時代,數(shù)據(jù)如同無形的血液,流動于信息網(wǎng)絡(luò)的每一個角落。無論是進(jìn)行智能對話、推薦內(nèi)容,還是提供各種服務(wù),背后都離不開數(shù)據(jù)的支撐。作為一個智能助手,我的信息究竟來自哪里?這些數(shù)據(jù)又是如何被處理和存儲的呢?這不僅是技術(shù)問題,更是關(guān)乎用戶信任與隱私的核心議題。
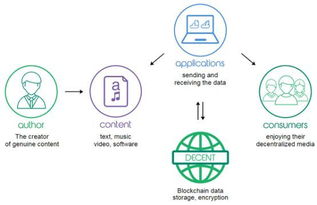
關(guān)于數(shù)據(jù)來源,我的知識庫主要來源于多個方面。最基礎(chǔ)的是通過大規(guī)模、公開、合法的文本數(shù)據(jù)集進(jìn)行訓(xùn)練,這些數(shù)據(jù)集涵蓋了百科全書、學(xué)術(shù)論文、新聞文章、書籍以及經(jīng)過篩選的網(wǎng)頁內(nèi)容等。這些數(shù)據(jù)在收集時通常遵循嚴(yán)格的版權(quán)與隱私法規(guī),確保不包含個人敏感信息。我的開發(fā)團(tuán)隊會持續(xù)用新的、高質(zhì)量的數(shù)據(jù)進(jìn)行迭代更新,以保持信息的時效性與準(zhǔn)確性。需要明確的是,我不會主動訪問用戶的個人數(shù)據(jù)(如聊天記錄、文件等)作為訓(xùn)練來源,除非用戶明確授權(quán)并用于改善特定服務(wù)。因此,在每次互動中,我提供的回答都基于既有的知識庫,而非實時抓取網(wǎng)絡(luò)信息。
數(shù)據(jù)處理是一個復(fù)雜而精細(xì)的過程。原始數(shù)據(jù)需要經(jīng)過清洗、去重、標(biāo)注和結(jié)構(gòu)化,以去除噪音和無關(guān)內(nèi)容。例如,文本數(shù)據(jù)會被分割成單詞或短語,通過自然語言處理技術(shù)分析語義和上下文。在這個過程中,隱私保護(hù)是關(guān)鍵原則:任何可能涉及個人身份的信息都會被匿名化或剔除。數(shù)據(jù)處理的目標(biāo)是構(gòu)建一個高效、可靠的模型,使其能夠理解并生成人類語言,同時避免偏見和錯誤。這依賴于先進(jìn)的算法和持續(xù)的優(yōu)化,團(tuán)隊會定期評估輸出質(zhì)量,并根據(jù)反饋進(jìn)行調(diào)整。
數(shù)據(jù)存儲服務(wù)則關(guān)注安全與可持續(xù)性。訓(xùn)練后的模型和相關(guān)數(shù)據(jù)通常存儲在高度安全的云服務(wù)器或?qū)S脭?shù)據(jù)中心,這些設(shè)施采用加密技術(shù)、訪問控制和備份機(jī)制,以防止未經(jīng)授權(quán)的訪問或數(shù)據(jù)丟失。存儲服務(wù)也遵循國際標(biāo)準(zhǔn)(如GDPR、CCPA等),確保合規(guī)性。在用戶交互中,臨時數(shù)據(jù)(如單次對話內(nèi)容)可能被短暫緩存以提升響應(yīng)速度,但除非用戶同意,否則不會長期保留。開發(fā)方會明確告知數(shù)據(jù)保留政策,并允許用戶管理自己的信息。
我的信息來源于公開、合規(guī)的數(shù)據(jù)集,并通過嚴(yán)格的處理和存儲流程來保障質(zhì)量與安全。透明度是建立信任的基石——作為用戶,了解這些背景有助于更放心地使用服務(wù)。隨著技術(shù)發(fā)展,數(shù)據(jù)倫理和隱私保護(hù)將持續(xù)成為焦點(diǎn),而我的目標(biāo)始終是:在提供有價值幫助的尊重每一個數(shù)字足跡。
如若轉(zhuǎn)載,請注明出處:http://m.gjjsy.cn/product/38.html
更新時間:2026-06-09 06:00:43